[Paper Review] Efficient Reinforced Feature Selection via Early Stopping Traverse Strategy 논문 리뷰
오늘 리뷰할 논문은 데이터마이닝 티어 학회인 IEEE/ICDM 2021년 게재 논문 중 하나인 "Efficient Reinforced Feature Selection via EarlyStopping Traverse Strategy"이다.
https://arxiv.org/pdf/2109.14180.pdf (게재 버전과 arxiv 버전 동일)
이 논문은 데이터마이닝 관련 연구라서 내 연구와 강화학습 이외에는 큰 연결고리가 없지만, 대학원 수업 과제로 발표해야 하는 김에 리뷰도 함께 작성하려고 한다.
(정리한 내용에 오류가 있을 수 있으니, 발견한다면 댓글로 알려주면 감사하겠습니다.)
1. 소개
본 논문에서는 데이터 전처리 기술 중 하나인 특징 선택(Feature Selection) 문제를 위해 다음과 같은 방법론을 제안한다.
- 단일 에이전트 몬테카를로 기반의 Reinforced Feature Selection 방법
- 학습 효율성 증가를 위한 조기 종료(early stopping) 전략과 보상 수준의 상호작용 전략
2. 연구 배경
일반적인 Data Mining 및 머신 러닝 파이프라인에서는 머신 러닝 작업을 진행하기 전에 먼저 데이터를 처리해야 한다.
전처리 기술에는 데이터 정제, 데이터 변환, 특징 엔지니어링(feature engineering) 등이 있는데,
이 중 가장 중요한 특징 엔지니어링 기술 중 하나인 특징 선택(feature selection)은 모델의 분류 정확도를 향상시키기 위해, 원본 데이터에서 가장 좋은 성능을 보여줄 수 있는 데이터의 부분집합(subset)을 찾아내는 기술이다.
기존의 특징 선택 방식들은 아래와 같이 구분할 수 있다.
- 기존 연구 1. 필터링 방식(filter methods) [1,2,3,4]

출처: https://analysisbugs.tistory.com/112
필터링 방식은 통계적 방식을 통해 미리 feature들을 걸러내는 전처리 과정을 사용하는 방법이다. (ex. 단변량 특징 선택, 상관관계 기반 특징 선택)
주로 피어슨 상관분석, 카이제곱검정 등의 통계적 방식을 사용하여 상관관계를 파악하며, 이를 기준으로 각 feature들을 순위를 매긴 후, 각 순위에 따라 선택하거나 선택하지 않음으로써 특징 부분 집합을 구성한다.
그러나, 특징 선택과 예측 모델 간의 특징 종속성 및 상호작용이 무시된다는 한계가 있다.
- 기존 연구 2. 래퍼 방식(wrapper methods) [7,8]

래퍼 방식은 [특징 조합 생성 -> 학습 진행 -> 성능 평가(정확도, AUC 등)]의 반복을 통해 가장 좋은 조합을 찾아내는 방법이다. 이때 조합을 생성하는 방법으로는 Forward Selection, Backward Elimination, Stepwise Selection 등이 있다.
그러나, 특징 개수에 비례하는 공간을 탐색하므로 많은 시간 비용이 요구되며, 과적합의 가능성이 크다는 한계가 있다.
- 기존 연구 3. 임베디드 방식(embedded methods) [9,10]
임베디드 방식은 모델 학습 및 생성 과정 자체에서 최적의 특징을 선택하는 방법으로, LASSO, Ridge Regression, Decision Tree 등이 대표적이다.
그러나, 예측 모델의 강력한 구조적 가정에 따르게 된다는 한계가 있다. (ex. 가중치가 0이 아닌 특징이 중요하다고 간주되는 등)
따라서 최근에는 강화학습을 이용한 강화학습 기반 특징 선택(Reinforced Feature Selection, RFS)이라는 새로운 방식이 등장하였다.

강화학습 기반 특징 선택(RFS)은 여러 명의 에이전트가 특징들을 선택하는 방법으로, 하나의 에이전트는 하나의 특징을 선택(제어)하며 모든 에이전트가 협력함으로써 최적의 특징 집합을 생성한다. 이는 강력한 전역적 탐색 능력으로 인해 기존 특징 선택 방법들 대비 우수성이 입증되었다.
하지만, 신경망을 정책으로 사용하는 각 에이전트 개수는 곧 특징 개수와 비례하기 때문에, 대규모 데이터셋에서는 적용하기 어렵다는 한계를 보인다.
따라서, 본 논문에서는 "강화학습 기반의 특징 선택의 효과를 유지하면서도 보다 실용적이고 효율적인 방법의 설계가 가능한가?"라는 문제를 풀고자 한다.
위와 같은 문제를 풀기 위해 해결해야하는 도전적 과제들은 다음과 같다.
- 이슈(1) 특징 선택 문제를 어떻게 적은 수의 에이전트로 재구성해야 하는가?
- 이슈(2) 이러한 순회 전략의 학습 효율성을 개선하기 위해 어떻게 해야하는가?
- 이슈(3) 어떻게 외부 조언/보상(external advice)을 이용하여 학습 효율 개선할 수 있을까?
각각의 도전적 과제들을 해결하기 위한 제안 방식은 아래에서 자세하게 소개한다.
2.5 선행 지식(Preliminaries)
아래 제안 방식을 읽기 전에 사전 지식을 정리한 아래 글을 읽으면 읽기 편할 것이다. MDP와 Monte Carlo에 관해 잘 알고 있다면 생략해도 무방하다.
2023.11.27 - [강화학습] - MDP와 Monte Carlo 개념 정리
3. 제안 방식
- 이슈(1) 특징 선택 문제를 어떻게 적은 수의 에이전트로 재구성해야 하는가?
본 논문에서는 하나의 에이전트가 각 특징을 하나씩 방문하여 선택O or 선택X를 결정하는 순회(traverse) 전략을 사용한다. 즉, 한 에이전트가 모든 특징 집합을 각각 탐색한 후, 선택한 각 특징들로 구성된 특징 부분 집합(subset)을 얻는 방식이다.
이때, 제안 모델은 off-policy 기반으로, (1) 행동 정책(behavior policy) b와 (2) 목표 정책(target policy) pi의 2가지 정책을 구분한다.
* 기본 정의
- 학습 에피소드는 일련의 {state, action, reward}의 샘플들로 구성
- 선택한 특징 부분 집합을 환경으로, 그 특징의 표현(representation)들을 state로 간주
- 행동은 0(선택X)/1(선택O)로, 보상은 예측 정확도, 특징 부분 집합 관련성 및 중복성으로 구성
(1) 행동 정책(behavior policy)
- 학습 데이터 생성 역할
- 매 학습 iteration마다 특징 집합을 순회하면서 하나의 학습 에피소드 생성
- 학습 에피소드를 사용하여 중요도 샘플링을 Q-value으로 계산하여 목표 정책을 평가하고, 벨만 방정식(Bellman equation)으로 개선 -> 반복할수록 target policy의 성능이 좋아짐
(2) 목표 정책(target policy)
- 최종 특징 부분 집합 생성 역할
- 학습이 완료되면 target policy를 사용하여 특징 집합을 탐색하고, 최적의 특징 부분 집합을 도출
-> 행동 정책은 더 높은 품질의 학습 데이터를 생성하기 위해 목표 정책을 최대한 커버해야 하며, 탐색을 가능하게 하기 위해 무작위성을 도입해야 한다.

순회 방법은 위의 알고리즘과 같다.
먼저, 행동 정책이 각 특징을 순회하면서, 아래 수식과 같이 epsilon-greedy 방식을 통해 행동을 선택한다.

이를 통해 각 상태에서 행동을 수행하고, 이로부터 MDP로 표현되는 에피소드 샘플을 획득한다.

이후, 모든 특징을 순회하였다면 저장한 에피소드들을 이용하여 목표 정책과 행동 정책을 갱신한다.
이때, 목표 정책의 greedy 정책으로, 아래 수식과 같이 계산된다.

수집된 에피소드 샘플들은 모두 행동 정책의 분포를 따르고, 정책 갱신을 위한 가치 함수는 목표 정책으로 계산됨
또한, 두 정책이 서로 다른 분포를 가지고 있으므로 아래 수식과 같이 중요도 샘플링을 기반으로 학습한다.


- 이슈(2) 이러한 순회 전략의 학습 효율성을 개선하기 위해 어떻게 해야하는가?

그러나, 앞서 말한 순회 방식은 연속적이고, 중요도 샘플링 가중치 방식에 의존적이기 때문에 특정 시점(T)의 샘플이 왜곡(skew)되면 그 이후 샘플도 왜곡되어 학습에 방해가 된다는 문제가 존재한다. 따라서, 이러한 순회 전략의 학습 효율성을 개선하기 위해 중요도 샘플링 가중치를 기반으로 조기 종료 전략을 사용하였다.

바로 이 종료 기준을 통해 에피소드 생성을 중단하고, 이 종료 기준을 이용하여 적절한 가중치를 다시 계산함으로써 행동 정책의 샘플을 목표 정책에 가깝게 만드는 방법이다. 이때, 종료 기준은 중요도 샘플링 가중치를 활용하여 아래 수식과 같이 재계산된다.

이때 p_v^i는 아래 수식과 같이 계산하며, i번째 에피소드의 모든 샘플에 대해 동일하다. 따라서 위의 수식에서 곱하더라도 값이 거의 증가하지 않는다.
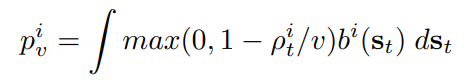
- 이슈(3) 어떻게 외부 조언/보상(external advice)을 이용하여 학습 효율 개선할 수 있을까?

* Interactive Reinforcement Learning(IRL) :
환경으로부터의 학습과 함께 외부 어드바이저(advisor)의 조언을 함께 사용함으로써 학습 과정을 가속화할 수 있는 강화학습의 한 방식. (즉, 강화학습은 환경으로부터만 / 모방학습은 외부 전문가로부터만 / IRL은 환경과 외부 조언가로부터 학습한다!)
특히, apprenticeship 과정을 벗어날 수 있도록 돕기 위해선 어떤 상태가 apprenticeship에 속하는지 식별해야 하므로, 조기 어드바이징, 중요도 어드바이징, 실수 수정 및 예측 어드바이징 등의 전략들이 있다.

본 논문에서 어드바이징 상태(advising state)의 개수를 N_a로 정의하며, 이 N_a가 t보다 크거나 같은 경우에만 apprenticeship라고 판단하여 state-action 쌍을 평가하는 효용함수 U를 추가한 보상을 사용한다. 이때, 보상 자체를 R이 아닌 R'로 효용함수 U가 통합된 보상함수를 사용한다.

4. 실험
4종류의 데이터셋에서의 검증 실험 진행하였다.
Forest Cover (FC), Spambase (Spam), Insurance Company Benchmark (ICB), Arrhythmia (Arrhy)

(1) [Filter Methods] K-Best : 레이블이 있는 비지도 점수로 특징의 순위를 매기고 가장 높은 점수를 받은 상위 k개의 특징을 선택하는 방법 -> k = N/2 (입력 특징 개수의 절반)
(2) [Embedded Methods] LASSO : L1-페널티를 통해 특징 선택을 수행하는 방법
-> 정규화 가중치 λ=0.15
(3) GFS : 크로스오버와 돌연변이를 통해 더 나은 특징 하위 집합을 생성하기 위해 각 특징에 대한 적합도를 계산하여 특징선택 방법
(4) mRMR : 특징의 중복성을 최소화하고 레이블과의 관련성을 최대화하여 특징의 순위를 매기는 방법
(5) RFE : 점점 더 작은 특징 하위 집합을 재귀적으로 선택하여 특징을 선택하는 방법
(6) [RFS Methods] MARFS : 다중 에이전트 강화 학습 기반의 특징 선택 방법 -> M개의 에이전트-특징 관리
(7) [RFS Methods] MCRFS : 조기 종료(early stopping)을 제외한 본 논문의 제안 방법

-> CPU / Memory 점유율 비교 à MCRFS가 훨씬 적은 계산 리소스를 사용하는 것을 확인할 수 있다.
5. 결론
본 논문에서는 강화학습 기반 특징 선택(RFS)의 학습 효율을 개선하기 위해 아래와 같은 2가지를 제안하였다.
(1) 순회(traverse) 전략을 통해 단일 에이전트 프레임워크로 단순화하고, 이를 몬테카를로 방법으로 구현하고자 함
=> 단일 에이전트를 통해 계산 자원의 요구량/하드웨어 점유율을 줄일 수 있었음
(2) 두 가지 전략(조기 종료, 외부 조언)을 통해 프레임워크의 효율성을 개선하고자 함
=> 학습 효율을 향상시키고, 정책을 변경하지 않아도 학습 과정을 가속화할 수 있었음
[향후 연구]
1) 병렬 프레임워크에 적용하여 1개 이상의 에이전트가 함께 작업하여 순회?
2) 대화형 강화 학습은 보상 수준 외에도 행동 수준과 샘플링 수준에서의 조언?
3) Deep Q Network, Actor-Critic, Proximal Policy Optimization(PPO) 등 다른 강화 학습 프레임워크에서의 구현?